

خوشه بندی روی داده buddymove holidayiq
در این نوشته به بررسی یک تمرین و پروژهی عملی شناسایی الگو به صورت رایگان را داریم. بعد از اتمام این نوشته شما به صورت عملی و با کدهای متلب دیتاست buddymove holidayiq را خوشه بندی میکنید. در این آموزش خوشه بندی با روشهای TTSAS – Fuzzy cMeans – min proximity – max proximity را انجام میدهیم. پایهی خوشه بندی در این نوشته با کدهای متلب است.
خوشه بندی روی داده buddymove holidayiq
الگو شناسی یا تشخیص الگو شاخهای از مباحث یادگیری ماشین در هوش مصنوعی است. میتوان گفت تشخیص الگو یا شناسایی الگو، دریافت دادههای خام و تصمیم گیری بر اساس دسته بندی دادهها یا classification است. قبل از مطالعهی این نوشته اگر پیش نیاز یادگیری مباحث شناسایی الگو (الگو شناسی) و متلب را دارید به شما مطالعهی کتابهای زیر معرفی میشود:
خوشه بندی از لحاظ دسته بندی در دستهی الگوریتمهای یادگیری نظارت نشده یا unsupervised learning است. در راستای توسعهی محتوای وب فارسی دیتاستهای فارسی زیر در وبسایت ما موجود است:
- دیتاست کلمات بد فارسی.
- دیتاست های دیجی کالا.
- دیتاست سایت دیوار.
- بانک کلمات معنادار زبان فارسی.
- دیتاست کلمات فارسی به انگلیسی برای دیکشنری.
دیتاست buddymove holidayiq
این دیتاست شامل ستونهای زیر است:
- Sports.
- Religious.
- Nature.
- Theatre.
- Shopping.
- Picnic.
در این دیتاست 249 سطر داده قرار دارد؛ فیلدهای این دیتاست همه به صورت عددی می باشد و نرمال شده نمی باشد و مقادیر آنها خارج از محدوده ی 0 تا 1 است.
برای مطالعه ی بیشتر در ارتباط با این دیتاست روی این لینک کلیک کنید. (این دیتاست در آرشیو UCI قرار دارد.)
لینک دانلود مستقیم دیتاست buddymove holidayiq :
دانلود مستقیم – دانلود غیر مستقیم
عملیات خوشه بندی روی buddymove holidayiq
خوشه بندی به روش TTSAS
ابتدا دیتاست را دانلود کنید و یک اسکریپت جدید با نام example_ttsas.m بسازید؛ کد اسکریپت example_ttsas.m به شرح زیر است:
clc;
clear;
close all;
% Amir Shokri
% amirsh.nll@gmail.com
% github.com/amirshnll
% July 2020
% Load Data
dataFile = importdata('buddymove_holidayiq.csv');
data = dataFile.data;
textdata = dataFile.textdata;
colheaders = dataFile.colheaders;
% Data Normalized
data_normal = normalize(data,'range');
% TTSAS Algorithm
theta1 = 2.2;
theta2 = 4;
TTSAS_labels = TTSAS(data,theta1,theta2);
figure, scatter( data(:,1), data(:,2), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,1), data(:,3), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,1), data(:,4), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,1), data(:,5), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,1), data(:,6), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,2), data(:,3), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,2), data(:,4), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,2), data(:,5), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,2), data(:,6), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,3), data(:,4), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,3), data(:,5), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,3), data(:,6), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,4), data(:,5), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,4), data(:,6), 5, TTSAS_labels, 'filled' );
figure, scatter( data(:,5), data(:,6), 5, TTSAS_labels, 'filled' );
در کنار اسکریپت بالا توابع دیگری نیز باید ساخته شود:
اسکریپت getClusterRepresentative.m :
function rep = getClusterRepresentative(inds, X) % Amir Shokri % amirsh.nll@gmail.com % github.com/amirshnll % July 2020 rep = mean( X(inds,:), 1 )'; end
اسکریپت findClosestCluster.m :
function [d_x_i_C_k,k] = findClosestCluster( ii, labels, X ) % Amir Shokri % amirsh.nll@gmail.com % github.com/amirshnll % July 2020 ulabels = unique(labels); if( ulabels(1)==0 ) ulabels = ulabels(2:end); end x_ii_to_cluster = []; for lab = ulabels, inds = find( labels==lab ); rep = getClusterRepresentative( inds, X ); d = sqrt( ( X(ii,:)' - rep )' * ( X(ii,:)' - rep ) ); x_ii_to_cluster = [ x_ii_to_cluster, d ]; end [d_x_i_C_k,mind] = min(x_ii_to_cluster); k = ulabels(mind);
اسکریپت estimateNumberOfClusters.m :
function [thetas,numFoundClusters] = estimateNumberOfClusters(X,s,Nsteps, q)
% Amir Shokri
% amirsh.nll@gmail.com
% github.com/amirshnll
% July 2020
N = size(X,1);
nFeatures = size(X,2);
Xd = pdist(X, 'euclidean');
a = min(Xd);
b = max(Xd);
thetas = linspace( a, b, Nsteps );
numFoundClusters = zeros( s, Nsteps );
for ti = 1:Nsteps,
t = thetas(ti);
for si = 1:s,
labs = BSAS( X(randperm(N),:), t, q );
numFoundClusters(si,ti) = length(unique(labs));
end
end
اسکریپت TTSAS.m :
function labels = TTSAS(X,theta1,theta2)
% Amir Shokri
% amirsh.nll@gmail.com
% github.com/amirshnll
% July 2020
N = size(X,1);
nFeatures = size(X,2);
m = 0;
is_labeled = zeros(N,1);
prev_change = 0;
cur_change = 0;
exists_change = 0;
labels = zeros(1,N);
while( sum(is_labeled)<N )
first_in_while_loop = 1;
for ii=1:N
if( is_labeled(ii)==0 && first_in_while_loop==1 && exists_change==0 )
first_in_while_loop = 0;
m = m+1;
labels(ii) = m;
is_labeled(ii) = 1;
cur_change = cur_change + 1;
elseif( is_labeled(ii)==0 )
[d_x_i_C_k,k] = findClosestCluster( ii, labels, X );
if( d_x_i_C_k < theta1 )
labels(ii) = k;
is_labeled(ii) = 1;
cur_change = cur_change + 1;
elseif( d_x_i_C_k > theta2 )
m = m+1;
labels(ii) = m;
is_labeled(ii) = 1;
cur_change = cur_change + 1;
end
elseif( is_labeled(ii)==1 )
cur_change = cur_change + 1;
else
fprintf('should never get here\n');
end
end
exists_change = abs( cur_change - prev_change );
prev_change = cur_change;
cur_change = 0;
end
خروجی :
به علت خروجی های متفاوت و طولانی نشدن حجم این پست خروجی این روش را به طور کامل برای هر کدام نگذاشتیم در صورتی که نیاز به مشاهده خروجی های مختلف این روش دارید تصاویر این لینک را بررسی کنید.
خوشه بندی به روش Fuzzy cMeans
ابتدا دیتاست را دانلود کنید و یک اسکریپت جدید با نام Fuzzy_cMeans.m بسازید؛ کد اسکریپت Fuzzy_cMeans.m به شرح زیر است:
clc;
clear;
close all;
% Amir Shokri
% amirsh.nll@gmail.com
% github.com/amirshnll
% July 2020
% Load Data
dataFile = importdata('buddymove_holidayiq.csv');
data = dataFile.data;
textdata = dataFile.textdata;
colheaders = dataFile.colheaders;
% Data Normalized
data_normal = normalize(data,'range');
% Fuzzy c-Means Algorithm
options_fcm = [2 100 0.00001 false];
cluster_size = 5;
[C_fcm,U_fcm] = fcm(data,cluster_size,options_fcm);
maxU_fcm = max(U_fcm);
index_fcm = cell(cluster_size,1);
for i=1:cluster_size
index_fcm{i} = find(U_fcm(i,:) == maxU_fcm);
end
figure
hold on
for i=1:cluster_size
plot(dataset(index_fcm{i},1),dataset(index_fcm{i},2),'o')
plot(C_fcm(i,1),C_fcm(i,2),'x','MarkerSize',15,'LineWidth',2)
end
hold off
خروجی :
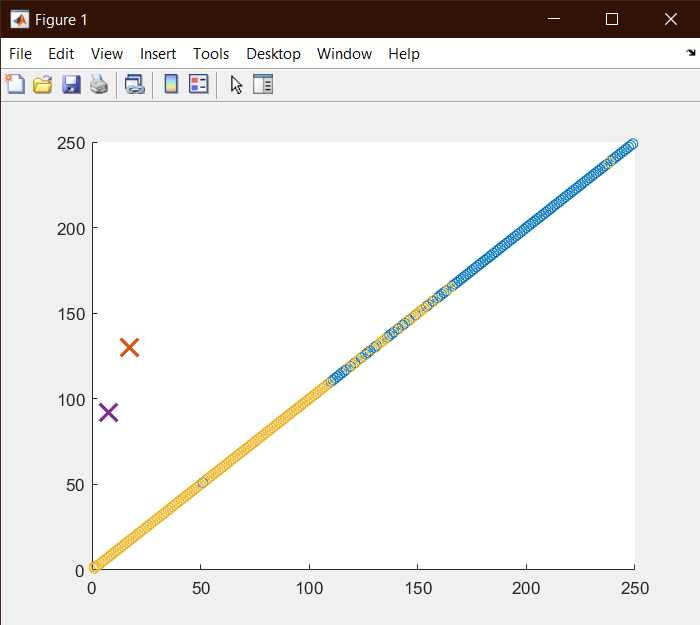
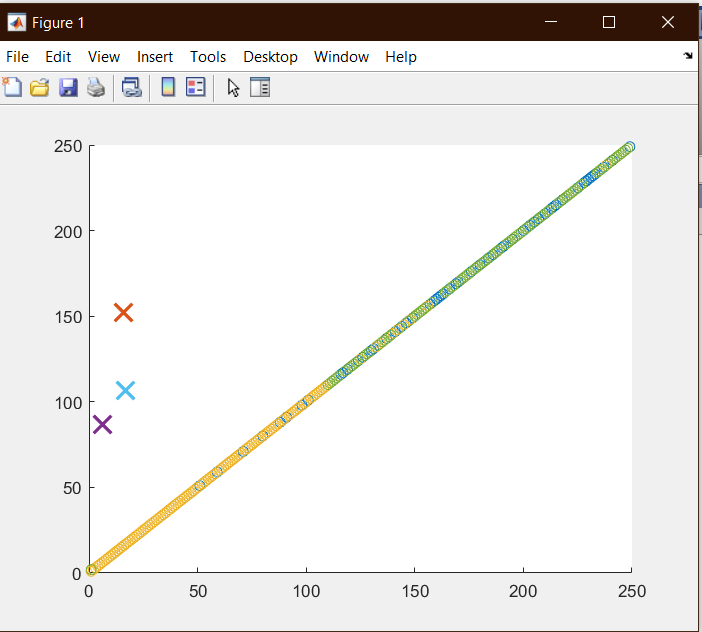

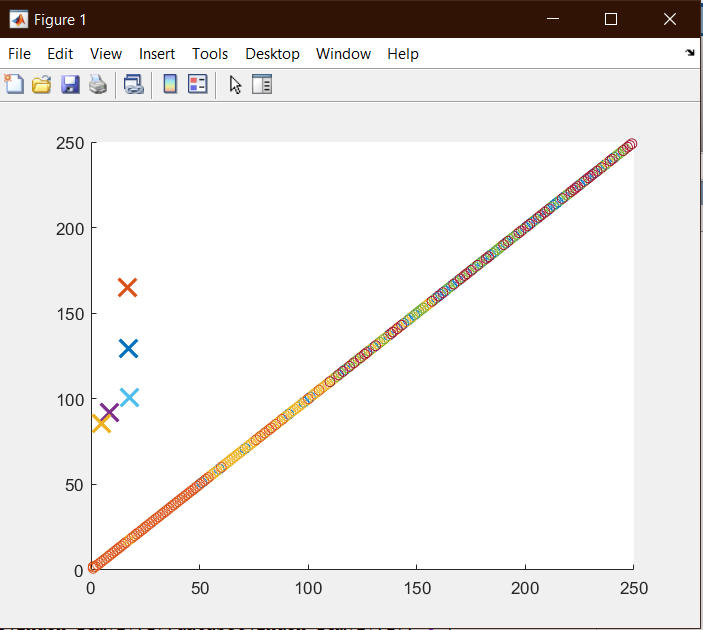
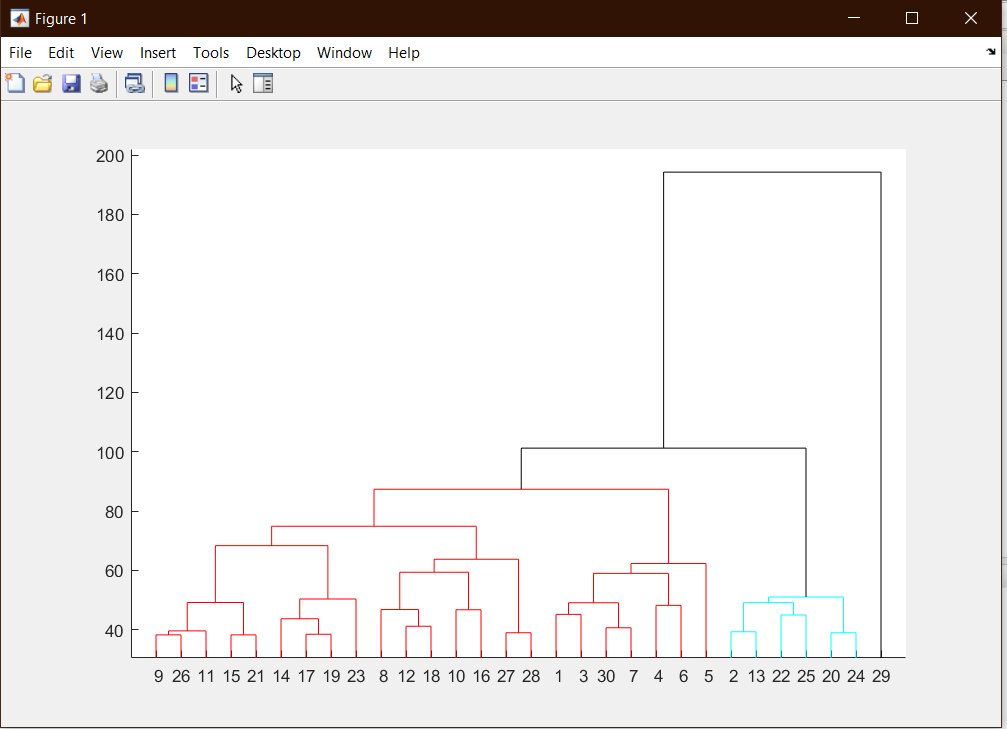
خوشه بندی به روش min proximity
ابتدا دیتاست را دانلود کنید و یک اسکریپت جدید با نام min_proximity.m بسازید؛ کد اسکریپت min_proximity.m به شرح زیر است:
clc;
clear;
close all;
% Amir Shokri
% amirsh.nll@gmail.com
% github.com/amirshnll
% July 2020
% Load Data
dataFile = importdata('buddymove_holidayiq.csv');
data = dataFile.data;
textdata = dataFile.textdata;
colheaders = dataFile.colheaders;
% Data Normalized
data_normal = normalize(data,'range');
% Min Proximity
Z = linkage(data,'ward','chebychev');
T = cluster(Z,'maxclust',3);
cutoff = median([Z(end-2,3) Z(end-1,3)]);
dendrogram(Z,'ColorThreshold',cutoff)
خروجی :

خوشه بندی به روش max proximity
ابتدا دیتاست را دانلود کنید و یک اسکریپت جدید با نام max_proximity.m بسازید؛ کد اسکریپت max_proximity.m به شرح زیر است:
clc;
clear;
close all;
% Amir Shokri
% amirsh.nll@gmail.com
% github.com/amirshnll
% July 2020
% Load Data
dataFile = importdata('buddymove_holidayiq.csv');
data = dataFile.data;
textdata = dataFile.textdata;
colheaders = dataFile.colheaders;
% Data Normalized
data_normal = normalize(data,'range');
% Max Proximity
Z = linkage(data,'average','chebychev');
T = cluster(Z,'maxclust',3);
cutoff = median([Z(end-2,3) Z(end-1,3)]);
dendrogram(Z,'ColorThreshold',cutoff)
خروجی :
اگر بخشی از کد بالا اشتباه است یا کد بهتری مد نظر دارید از بخش نظرات به اطلاع ما برسانید.
در ارتباط با شاخه های مختلف هوش مصنوعی در این لینک بیشتر بخوانید.
پایدار باشید.