

پاسخ نظرات سایت وردپرس با api جمینای و گوگل
در این نوشته چالش پاسخ نظرات سایت وردپرسی شما را به کمک api گوگل جمینای توضیح میدهیم.
پاسخ تمام نظرات سایت وردپرس با api جمینای و گوگل + پایتون
ابتدا با دستور pip کتابخانههای زیر را نصب کنید:
pip install google-genai pandas openpyxl
سپس وارد سایت aistudio.google.com/api-keys شوید. سپس یک کلید API بسازید. برای اینکار مراحل زیر را دنبال کنید:

روی کلید Create API key بزنید سپس:
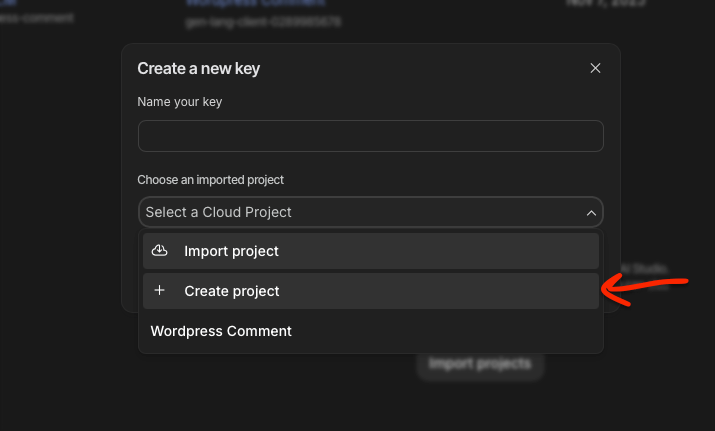
سپس در پنجرهی باز شده روی Choose an imported project بزنید و در آن گزینهی Create project را بزنید.
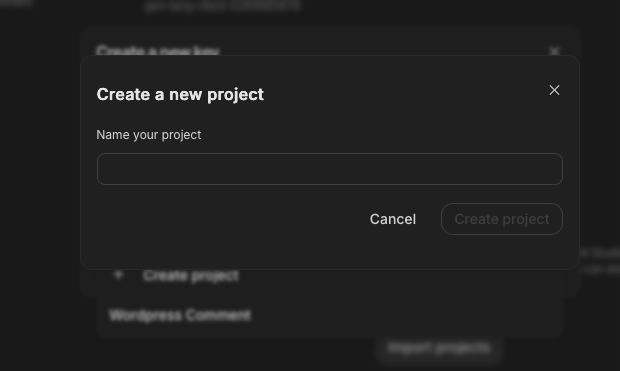
سپس برای پروژهی خود یک اسم انتخاب کنید. در مرحلهی بعد:
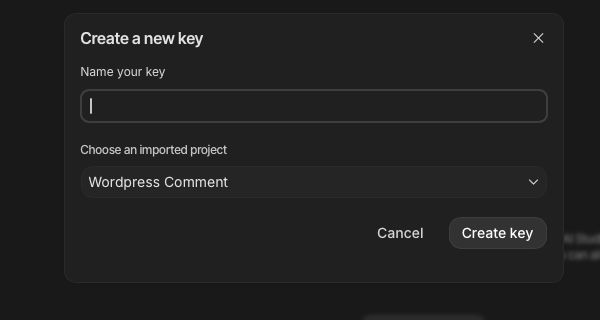
برای کلید API خود یک نام انتخاب کنید و سپس روی کلید Create key بزنید.
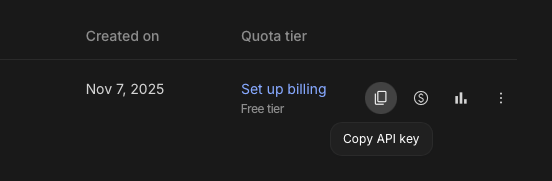
در آخر بعد از ساخت روی کلید Copy API Key بزنید.
حالا یک کد ادیتور باز کنید و کد زیر را کپی کنید و با نام answer.py ذخیره کنید.
import sys
import xml.etree.ElementTree as ET
from typing import List, Dict
import pandas as pd
from datetime import datetime
import time
import os
import json
from google import genai
from google.genai import types
try:
client = genai.Client()
except Exception as e:
print(
"Error initializing Gemini client. Make sure GEMINI_API_KEY is set.",
file=sys.stderr,
)
pass
# GEMINI_MODEL = "gemini-2.0-flash-lite"
# REQUESTS_PER_MINUTE = 29
# GEMINI_MODEL = "gemini-2.5-flash"
# REQUESTS_PER_MINUTE = 10
# GEMINI_MODEL = "gemini-2.0-flash-exp"
# REQUESTS_PER_MINUTE = 10
GEMINI_MODEL = "gemini-2.5-flash-lite"
REQUESTS_PER_MINUTE = 15
# GEMINI_MODEL = "gemini-2.0-flash"
# REQUESTS_PER_MINUTE = 15
# GEMINI_MODEL = "gemini-2.5-pro"
# REQUESTS_PER_MINUTE = 2
# GEMINI_MODEL = "learnlm-2.0-flash-experimental"
# REQUESTS_PER_MINUTE = 15
CommentData = Dict[str, str]
CHECKPOINT_FILE = "checkpoint.json"
def load_xml(filename: str) -> ET.Element:
try:
tree = ET.parse(filename)
return tree.getroot()
except FileNotFoundError:
print(f"Error: File '{filename}' not found.", file=sys.stderr)
sys.exit(1)
except ET.ParseError:
print(f"Error: Could not parse XML from '{filename}'.", file=sys.stderr)
sys.exit(1)
def extract_comments(root: ET.Element) -> List[CommentData]:
ns = {
"wp": "http://wordpress.org/export/1.2/",
"content": "http://purl.org/rss/1.0/modules/content/",
}
comments_to_approve: List[CommentData] = []
for item in root.findall("channel/item"):
post_title = (
item.find("title").text if item.find("title") is not None else "No Title"
)
post_content_elem = item.find("content:encoded", ns)
post_content = (
post_content_elem.text if post_content_elem is not None else "No Content"
)
post_id_elem = item.find("wp:post_id", ns)
post_id = post_id_elem.text if post_id_elem is not None else "Anonymous"
for comment in item.findall("wp:comment", ns):
approved_elem = comment.find("wp:comment_approved", ns)
approved = approved_elem.text if approved_elem is not None else "1"
if approved == "0":
comment_author_elem = comment.find("wp:comment_author", ns)
comment_author = (
comment_author_elem.text
if comment_author_elem is not None
else "Anonymous"
)
comment_content_elem = comment.find("wp:comment_content", ns)
comment_content = (
comment_content_elem.text
if comment_content_elem is not None
else "No Comment Content"
)
# Extract comment date
comment_date_elem = comment.find("wp:comment_date", ns)
comment_date_text = (
comment_date_elem.text if comment_date_elem is not None else ""
)
try:
comment_date = datetime.strptime(
comment_date_text, "%Y-%m-%d %H:%M:%S"
)
except Exception:
comment_date = datetime.min # If date is invalid
comments_to_approve.append(
{
"post_id": post_id,
"post_title": post_title,
"post_content": post_content,
"comment_author": comment_author,
"comment_content": comment_content,
"comment_date": comment_date,
}
)
return comments_to_approve
def generate_reply(comment: CommentData) -> str:
prompt = f"""
شما یک پست فارسی دارید:
عنوان پست:
{comment['post_title']}
محتوای کامل پست:
{comment['post_content']}
یک کامنت فارسی برای این پست دریافت شده:
نام نویسنده کامنت: {comment['comment_author']}
متن کامنت:
{comment['comment_content']}
لطفاً یک پاسخ **کوتاه، مودبانه و مرتبط** در حد یک یا دو جمله به این کامنت تولید کنید. پاسخ باید به زبان فارسی باشد. اسم نویسنده کامنت رو توی جوابت ننویس.
"""
try:
response = client.models.generate_content(
model=GEMINI_MODEL,
contents=prompt,
config=types.GenerateContentConfig(
max_output_tokens=150,
temperature=0.4,
),
)
if response.text and response.text.strip():
return response.text.strip()
elif response.candidates:
candidate = response.candidates[0]
finish_reason = candidate.finish_reason.name
if finish_reason == "SAFETY":
return "❌ Response blocked due to safety filter."
elif finish_reason == "MAX_TOKENS":
return "❌ Response incomplete due to token limit."
else:
return f"❌ Error: Finish reason: {finish_reason}"
else:
return "❌ No response generated."
except Exception as e:
return f"❌ API Error: {e}"
def load_checkpoint() -> List[Dict]:
if os.path.exists(CHECKPOINT_FILE):
with open(CHECKPOINT_FILE, "r", encoding="utf-8") as f:
return json.load(f)
return []
def save_checkpoint(data: List[Dict]):
with open(CHECKPOINT_FILE, "w", encoding="utf-8") as f:
json.dump(data, f, default=str, ensure_ascii=False)
def main():
if len(sys.argv) != 2:
print('Usage: python answer.py "WordPress.xml"')
sys.exit(1)
filename = sys.argv[1]
root = load_xml(filename)
comments = extract_comments(root)
if not comments:
print("No pending comments found (wp:comment_approved = '0').")
return
comments.sort(key=lambda x: x["comment_date"])
completed_replies = load_checkpoint()
completed_post_ids = {r["post_id"] + r["comment_author"] for r in completed_replies}
pending_comments = [
c
for c in comments
if (c["post_id"] + c["comment_author"]) not in completed_post_ids
]
print(f"Found {len(pending_comments)} pending comments. Generating replies...")
print("=" * 60)
for idx, c in enumerate(pending_comments, start=1):
reply = generate_reply(c)
completed_replies.append(
{
"post_id": c["post_id"],
"post_title": c["post_title"],
"comment_author": c["comment_author"],
"comment_content": c["comment_content"],
"comment_date": str(c["comment_date"]),
"reply": reply,
}
)
print(f"💬 Reply to {c['comment_author']}: {reply}")
save_checkpoint(completed_replies)
if idx % REQUESTS_PER_MINUTE == 0:
print("⏳ Waiting to respect the 1-minute rate limit...")
time.sleep(60)
df = pd.DataFrame(completed_replies)
df.to_excel("comment_replies.xlsx", index=False)
print("✅ All replies saved to 'comment_replies.xlsx'.")
if __name__ == "__main__":
main()
سپس به در ترمینال خود کد زیر را اجرا کنید:
export GEMINI_API_KEY="APIKEYTEST"
به جای APIKEYTEST کلیدی که ساختهاید را قرار دهید.
حالا به پنل سایت وردپرس خود بروید و در بخش برونبری یک برونبری از تمام نوشتههای خود دریافت کنید و این فایل را در کنار فایل answer.py قرار دهید.
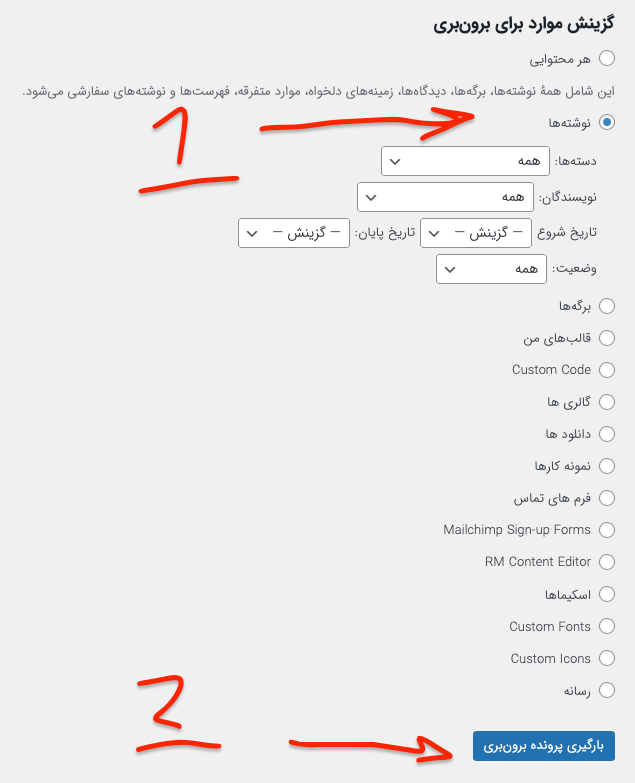
حالا کد زیر را در ترمینال خود اجرا کنید:
python answer.py WordPress.xml
از متصل بودن (و.ی.پ.ی.ا.ن) خود مطمئن باشید و سپس منتظر بمانید. در نسخهی رایگان محدودیتهایی وجود دارد که با تغییر مدل خود میتوانید این محدودیت را پشت سر بگذارید و با سرعت کمتری پاسخهای خود را دریافت کنید.
پس از اتمام اجرای کد بالا و پاسخدهی به تمام کامنتهای شما یک فایل با نام comment_replies.xlsx در مسیر جاری شما به وجود میآید.
اگر سوالی در ارتباط با این نوشته دارید در بخش نظرات همین نوشته برای ما بنویسید.